The augmented medallion architecture - Bronze Layer
"Bronze" layer
Published on : April 15, 2025
| Lastly edited on : April 15, 2025
| 5 minutes read

Lirav DUVSHANI
Series : The augmented medallion architecture
A standard architecture to analytics data platform
"Bronze" layer
"Silver" layer
"Gold" layer
"Platinum" layer
"Parametrization" layer
"Data Quality" layer
The Bronze layer - Where all the source data is stored
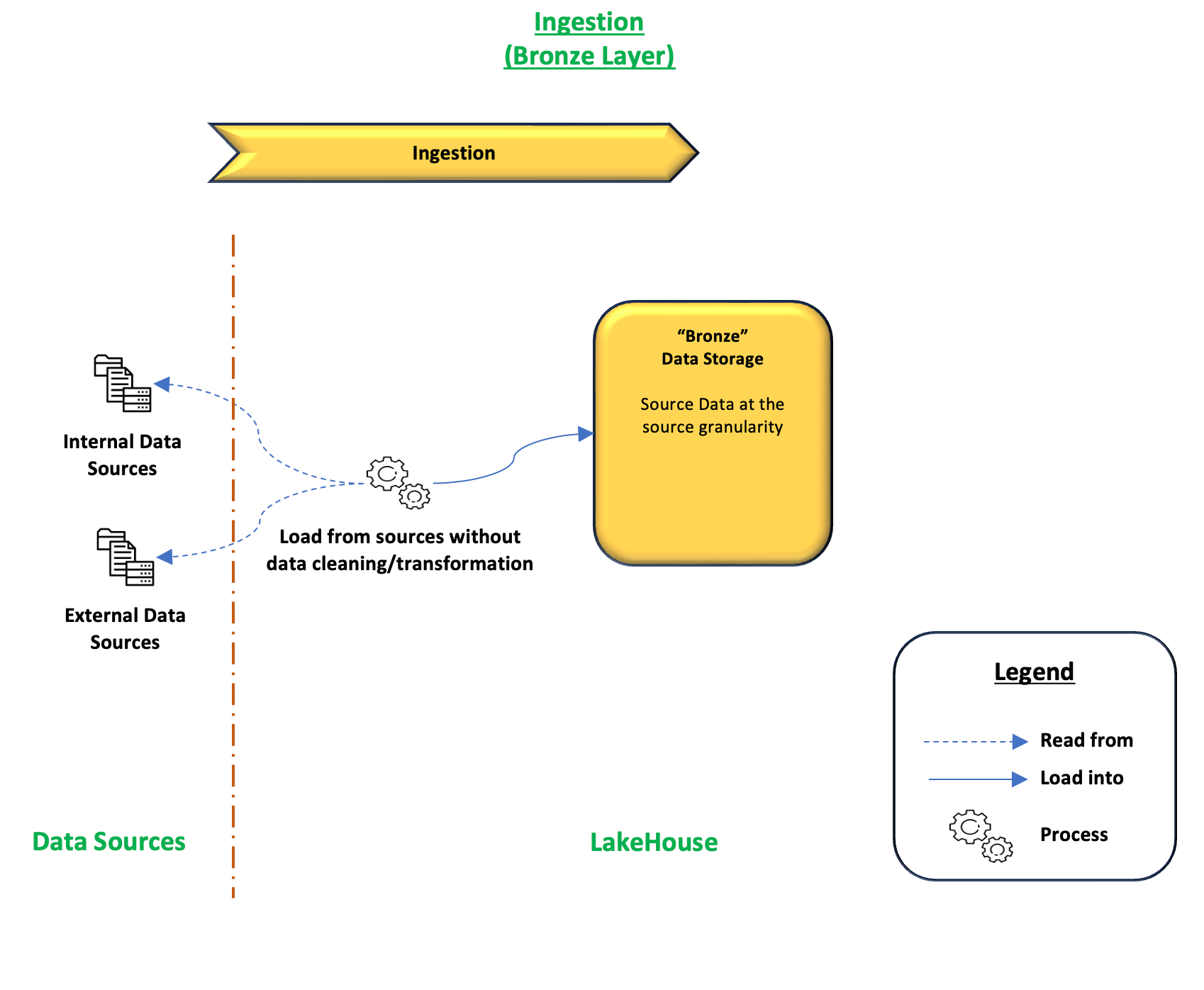
Purpose of the layer
The main purpose of this layer is to provide a similar structure for all data, whatever the data source, in a similar format enabling data analysis on raw data. While also being the source for all the data pipelines to be built in the Silver and Gold layers.
The secondary purposes of this layer are to :
- Complete data retention : Ensure the complete history of the data is available
- Reproductibility for Silver and Gold layers : With the complete data retention, any change in rules in the Silver and Gold layers can easily be reproduced in the past, thus allowing reprocessing of the data based on the Bronze layer
Although this layer should be complete, it might be required to anonymize the data or to keep only a specific scope of data.
This should be done in the Bronze data layer to ensure no data should be present in the platform that should not be.
Characteristics of the layer
- Storage should be immutable
- The data should never be deleted, and the load should be append-only, to preserve the complete history of the data
- Allowed Data Structures
- Structured
- Semi-Structured (JSON, XML, YAML, ...)
- Unstructured (text files, images, videos)
- Granularity of data
- The data should be detailed, at the same level of granularity as the source data
- Useful metadata information
- The extraction timestamp
- The load in bronze layer timestamp (also called ingestion timestamp)
- (if available) The last update of records in the source system
Good practices
In this layer, it is a good practice to structure this layer in a standard way for all types of data structures.
Also, tracking as much metadata information as possible is very beneficial for data analysis purposes and for monitoring reporting. Such information are the source extraction timestamp or the ingestion timestamp.
Examples
Structured data
Structure data can be stored as :
- Inside an object storage
- As a file format for flatten data (like csv, parquet or avro)
- As a compressed file containing flatten data (like gzip, zip or any other compressed format)
- Inside a database
- Inside a table
The data should be structured to enable easy access to the metadata information, like timestamp of load in bronze layer
Considering a bronze layer in an object storage, the files should be structured as follows :
- Sample csv storage
- 2025-01-02T03:55:02.728Z
- data.csv
- 2025-01-03T03:52:03.127Z
- data.csv
- 2025-01-04T04:02:42.009Z
- data.csv
- 2025-01-02T03:55:02.728Z
- Sample gzip storage
- 2025-01-02T12:55:02.728Z
- data.gzip
- 2025-01-03T02:52:03.127Z
- data.gzip
- 2025-01-04T08:02:42.009Z
- data.gzip
- 2025-01-02T12:55:02.728Z
Considering a bronze layer in a database, the data should be structured as follows :
| Customer ID | Customer Name | Ingestion Timestamp |
|---|---|---|
| 1 | Customer A | 2025-01-02T03:55:02.728Z |
| 2 | Customer B | 2025-01-02T03:55:02.728Z |
| 3 | Customer C | 2025-01-02T03:55:02.728Z |
| 1 | Customer A. Corp | 2025-01-03T03:52:03.127Z |
| 3 | Customer C. Corp | 2025-01-04T04:02:42.009Z |
Semi-structured data
Semi-Structure data can be stored as :
- Inside an object storage
- As a file format for flatten data (like json, yaml, ...)
- As a compressed file containing flatten data (like gzip, zip or any other compressed format)
- Inside a database
- Inside a table
The data should be structured to enable easy access to the metadata information, like timestamp of load in bronze layer
Considering a bronze layer in an object storage, the files should be structured as follows :
- Sample json storage
- 2025-01-02T03:55:02.728Z
- data.json
- 2025-01-03T03:52:03.127Z
- data.json
- 2025-01-04T04:02:42.009Z
- data.json
- 2025-01-02T03:55:02.728Z
- Sample gzip storage
- 2025-01-02T12:55:02.728Z
- data.gzip
- 2025-01-03T02:52:03.127Z
- data.gzip
- 2025-01-04T08:02:42.009Z
- data.gzip
- 2025-01-02T12:55:02.728Z
Considering a bronze layer in a database, the data should be structured as follows :
| Customer ID | Customer Name | Customer Tags | Ingestion Timestamp |
|---|---|---|---|
| 1 | Customer A | {"sector": "Industry", "earnings_range": ">100M"} | 2025-01-02T03:55:02.728Z |
| 2 | Customer B | {"sector": "IT", "earnings_range": "10-100M"} | 2025-01-02T03:55:02.728Z |
| 3 | Customer C | {"sector": "Retail", "earnings_range": "<10M"} | 2025-01-02T03:55:02.728Z |
| 1 | Customer A | {"sector": "Industry", "earnings_range": ">100M"} | 2025-01-03T03:52:03.127Z |
| 3 | Customer C | {"sector": "Retail", "earnings_range": "<100M" , "billing_currency": "EUR"} | 2025-01-04T04:02:42.009Z |
Non structured data
Non-structured data can be stored as :
- Inside an object storage
- As a file
- As a compressed file
Storage for non-structured data can be simpler than for structured and semi-structured data, as this data is mostly loaded into this bronze layer for storage and direct usage.
This article is part of a series of article describing the augmented medallion architecture.